代码设计原则
一、当我们谈论设计模式/原则/思想时,我们在谈论什么?
我喜欢优雅和高效的代码,代码的逻辑应该直接了当,叫缺陷难以隐藏;尽量减少依赖关系,使之便于维护;依据某种分层战略完善错误处理代码;性能调至最优,省得引诱别人做没规矩的优化,搞出一堆乱来,整洁的代码只做好一件事。
– Bjarne Stroustrup C++ 语言发明者
从具体到抽象:
- 语言规范
- 命名
- 函数
- 注释
- 设计模式
- 23种设计模式
- 架构模式
- MVC
- MVVM
- 事件驱动架构
- 分层架构
- 微服务架构
- 设计思想
- SOLID原则
- DRY、KISS、YAGNI原则
- DDD 领域驱动设计
- 分治思想
- 函数分解
- 分层设计
- 写代码的两次创造(第一遍实现功能,第二遍重构优化)
- 服务拆分、数据库水平垂直拆分
- 工程师的匠心(不仅仅是交付工作,更需要对优雅代码有追求)
二、语言规范
-
有意义的命名
先看两段代码:
def get_items(n): list1 = [] for i in range(n): list1[i] = i * 2 return list1 def get_even_sequence(length): result = [] for i in range(length): result[i] = i * 2 return result一些命名原则:
- 使用有意义的命名(避免 list,data, d 等)
- 使用读得出来的命名(避免自定义的缩写, genymdhms -> generationTimestamp)
- 使用可搜索的名称(5 -> WORK_DAYS_PER_WEEK)
-
函数
- 短小
- 只做一件事
反面教材举例:
Customer 的 send_auth_message_and_generate_report()
-
注释
- 注释不能美化糟糕的代码,如果代码写了大量注释还是不能让阅读者看懂,那就是说明代码很糟糕了
- 用代码来阐述(即 代码即注释,好的命名和结构是基础)
- 好的注释是必须的信息,比如: 对意图的解释、某些警告、TODO、放大某些看起来不合理之物的重要性
- 能用函数或者变量名是别用注释,尽量不要用注释。注释是我们试图用代码表达意图失败时的补救措施。
三、设计模式
- 23 种设计模式
- 创建型模式
- 抽象工厂
- 生成器
- 工厂方法
- 原型
- 单例
- 结构性模式
- 适配器
- 桥接
- 组合
- 装饰器
- 外观
- 享元
- 代理
- 行为型模式
- 职责链
- 命令
- 解释器
- 迭代器
- 中介者
- 备忘录
- 观察者
- 状态
- 策略
- 模板方法
- 访问者
- 创建型模式
-
在开户项目中应用的设计模式
2.1 单例模式
http_service 模块的各种定义
2.2 简单工厂模式
AccountHelper
2.3 观察者
EventBus
2.4 策略模式
validator_strategy
2.4 桥接模式
account_service
四、设计思想和设计原则
- 六大设计原则(SOLID 原则)
-
Single Responsibility Principle:单一职责原则
一个类应该只有一个发生变化的原因
There should never be more than one reason for a class to change.函数、类要短小精悍,这样才容易被复用。同时也易于阅读和维护,减少了认知复杂度。
- 一个东西做一件事情,并把它做好
- 应该有且仅有一个原因引起类的变更
- 类的复杂度降低
- 可读性提高
- 可维护性提高
- 变更引起的风险降低
-
Open Closed Principle:开闭原则
一个软件实体,如类、模块和函数应该对扩展开放,对修改关闭
Software entities like classes, modules and functions should be open for extension but closed for modification设计类、模块、流程的时候要易于拓展,考虑到后续变化时可以从容应对。
-
让不能变的变不了,让可变的容易变
-
软件实体(类,模块,函数等)应该是可以扩展的,但是不可修改的
-
设计类、接口的时候,要能够角色转换从使用者角度考虑问题
举例: Tornado 中的
RequestHandler提供了很多可以被 override 的方法,方便使用者在无需修改Tornado代码的情况下,实现需要的功能class RequestHandler(object): def prepare(self) -> Optional[Awaitable[None]]: pass def on_finish(self) -> None: pass -
-
Liskov Substitution Principle:里氏替换原则
所有引用基类的地方必须能透明地使用其子类的对象
Functions that use use pointers or references to base classes must be able to use objects of derived classes without knowing it.-
抽象的东东能用具体的东东替代
-
所有引用基类的地方必须能透明地使用其子类
-
子类必须完全的实现父类的方法
-
子类可以有自己的个性
-
覆盖或实现父类的方法时输入参数可以被放大
-
覆盖或实现父类的方法时输出结果可以被缩小
-
-
Law of Demeter:迪米特法则 a.k.a Least Knowledge Principe: 最少知道原则
只与你的直接朋友交谈,不跟“陌生人”说话
Talk only to your immediate friends and not to strangers
(如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。)设计类的接口要简洁,不要暴露过多的成员给外部,要从使用者的角度去设计类。
- 不涉及到的就不应该关注
- 出现在成员变量,方法的输入输出参数中的类被称为朋友类
- 只和朋友交流
- 尽量内敛,少对外开放接口
- 高内聚低耦合
-
Interface Segregation Principle:接口隔离原则
不应该强迫客户端依赖于他们不使用的接口,一个类与另一个类的依赖关系应该依赖于尽可能小。
Clients should not be forced to depend upon interfaces that they don`t use.
The dependency of one class to another one should depend on the smallest possible.- 不相关的就不能强制被关注
- 不应该强迫使用者依赖于他们不用的方法
- 类间的依赖关系应该建立在最小的接口上
- 接口尽量要小
- 接口要高内聚
- 可提供定制
- 接口设计粒度要适度
-
Dependence Inversion Principle:依赖倒置原则
上层模块不应该依赖底层模块,它们都应该依赖于抽象。 抽象不应该依赖于细节,细节应该依赖于抽象。
High level modules should not depend upon low level modules. Both should depend upon abstractions.
Abstractions should not depend upon details. Details should depend upon abstractions.- 容易变的不能被公用
-
- KISS 原则(Keep It Simple,Stupid)
- DRY 原则(Don’t Repeat Yourself)
- YAGNI 原则 (You Ain’t Gonna Need It)
六、DDD 思想
DDD(Domain-Driven Design 领域驱动设计)是由Eric Evans最先提出,目的是对软件所涉及到的领域进行建模,以应对系统规模过大时引起的软件复杂性的问题。整个过程大概是这样的,开发团队和领域专家一起通过 通用语言(Ubiquitous Language)去理解和消化领域知识,从领域知识中提取和划分为一个一个的子领域(核心子域,通用子域,支撑子域),并在子领域上建立模型,再重复以上步骤,这样周而复始,构建出一套符合当前领域的模型。
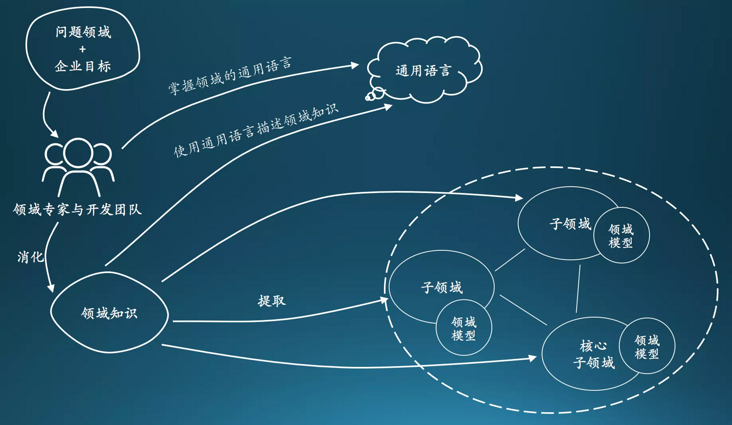
-
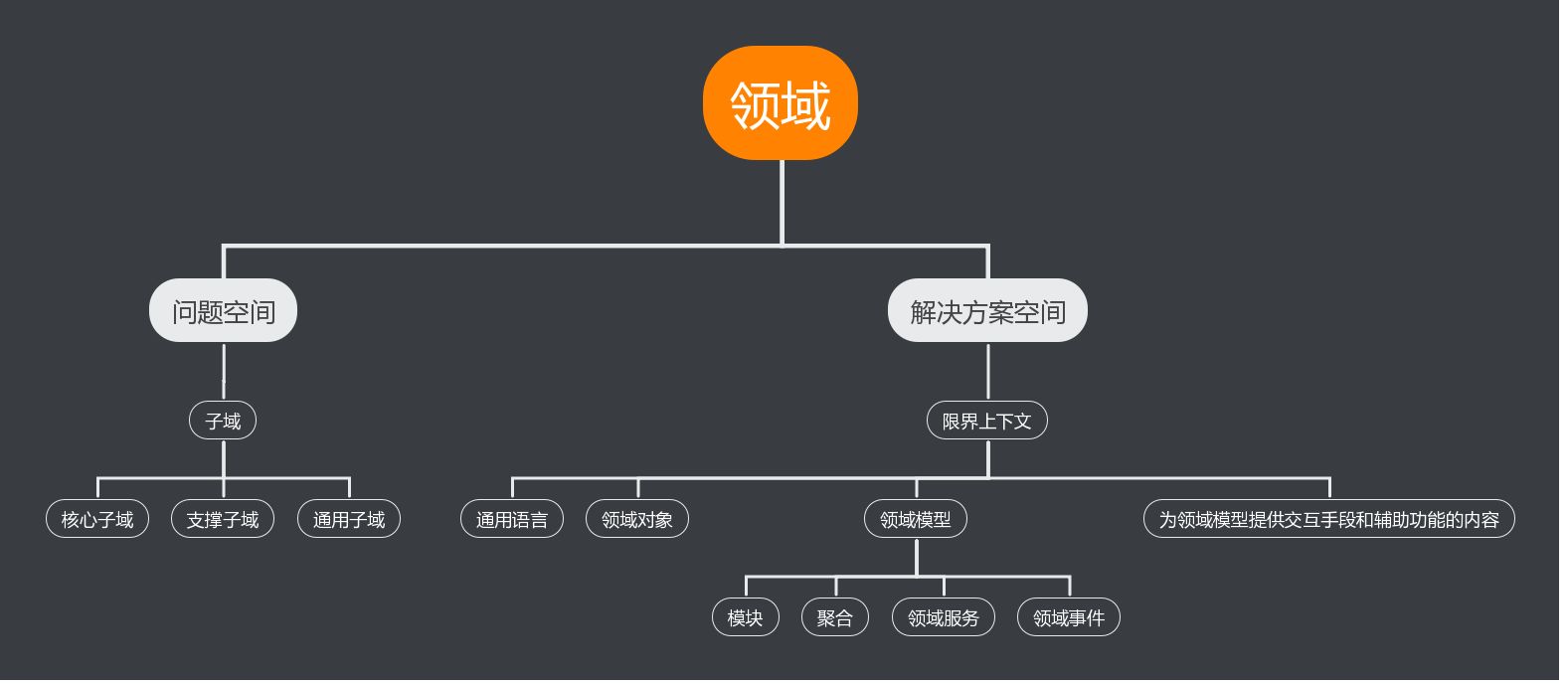
核心概念
1.1. 限界上下文 (Bounded Context)
一组概念接近、高度内聚并能找到清晰的边界的业务模型被称作限界上下文。 限界上下文可以视为逻辑上的微服务,或者单体应用中的一个组件。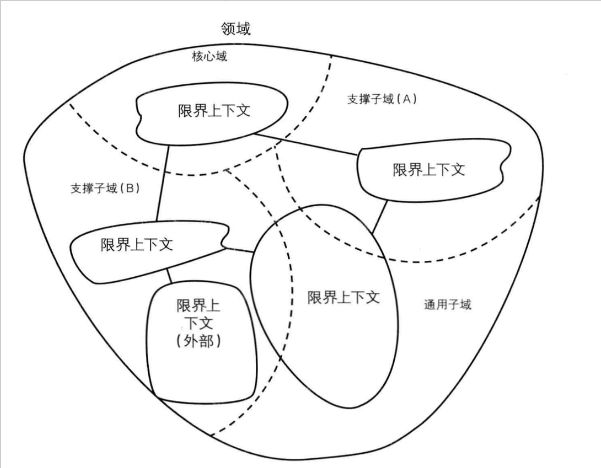
1.1.1. 通用语言
限界上下文中的每种领域术语、词组、或者句子都叫做通用语言,无论是领域专家和开发人员在对领域问题的沟通、需求的讨论,开发计划的制定、概念、还是代码中出现的类名与方法,都包括其中,而且要注意的一个规则是:只要是相同的意思,就应该使用相同的词汇。 通用语言有助于知识沉淀,降低沟通成本。1.1.2. 领域对象
实体类,它代表了业务的状态。可以看做是业务表。1.1.2. 领域模型
领域模型其实就是把通用语言表达成软件模型,领域模型包括了模块、聚合、领域事件和领域服务等1.2. 事件风暴 (EventStorming) (名字类似于头脑风暴)
事件风暴 梳理出一个业务流程中发生的事件,从而梳理出领域模型、子域。 事件风暴是划分界限上下文的手段。
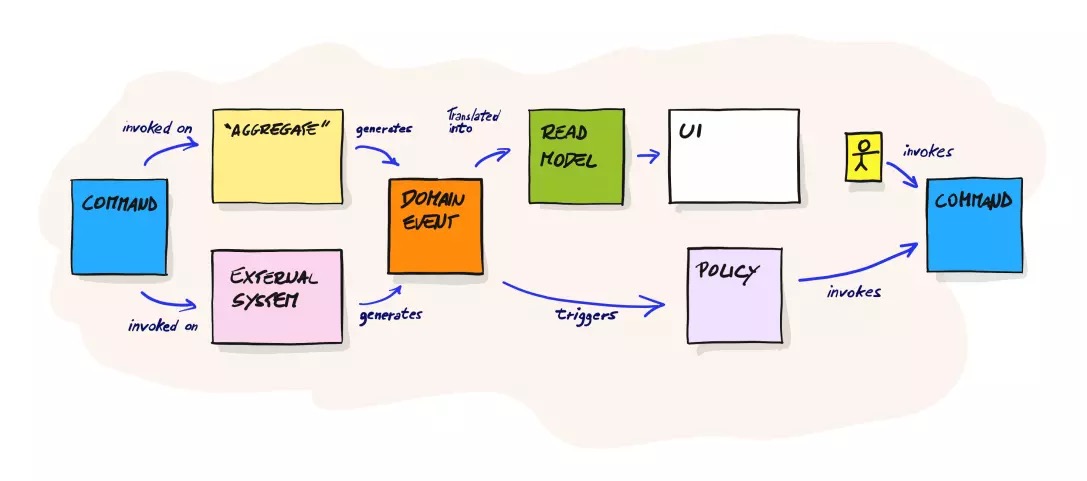
事件风暴的优点:
- 事件风暴的参与者是 业务人员和开发人员,使用的是通用语原而不是技术术语
- 令每个人聚焦于业务流程,而不是类和数据库
- 高度视觉化的方法,消除了实验过程中的代码,让每个人平等的参与到设计过程中;
- 团队成员无一例外地会取得对业理解的突破;
- 细粒度的事件为开发人员后续的研发提供了模型设计。
-
贫血模型与充血模型
# 贫血模型:Model 只做了数据结构定义,不包含业务逻辑,逻辑基本在服务层实现,代码集中在Service层 if account_obj.open_account_time != None and account_obj.open_account_time != 0: init_account_trade_permission() # 充血模型:充血模型的实体类里不但有状态,还有行为,即属性和方法都有。它的Service层很薄,业务逻辑只是完成对业务逻辑的封装、事务和权限等的处理。 if account_obj.is_open(): init_account_trade_permission()代码贫血症经常会引起失忆症(anemia and amnesia)
- 想不起来一段代码的作用
- 不知道修改一个功能需要去哪里修改
- 修改一个逻辑,需要修改大量的不同地方的代码
- 代码逻辑没有层次,超长函数实现,无法复用
六、代码质量的评判的评判标准
- 可阅读性(方便代码流转)
- 可扩展性 / 可维护性(方便修改功能,添加新功能)
- 可测试性(质量管理)
- 可复用性(简化后续功能开发的难度)
七、代码中的坏味道
- 重复的代码
- 长函数、过大的类 (是否违反单一职责?举例:face_verify_task )
- 无法说明一个类或者函数的作用(是否违反单一职责?功能边界是否清晰?)
- 过长的参数列表(可读性差)
- 过多的注释
- 增加新需求时难以实现,大量修改(可拓展性差,代码结构不合理)
- 循环引用(代码分层有问题)
- 散弹式修改(代码失忆症,举例:application_type)
延伸阅读参考:
[1] 《代码整洁之道》图书
[2] 《重构:改善既有代码的设计》 偏实践
[3] 《代码中的坏味道》极客时间电子课程
[4] 《图说设计模式》 电子文档
[5] 文章:Python代码风格指南
[8] 《许式伟的架构课》
[7] 文章:IDDD 实现领域驱动设计-由贫血导致的失忆症
[8] DDD: 事件风暴
[10] 用DDD指导微服务拆分
[11] 领域驱动设计(DDD)实践之路(一)
Back