上周被投诉我的 Python 进程占用了太多内存,并且持续增长。本来我不以为然,觉得应该是 Python 自己的 GC 并不是那么及时。然而加上手动的 GC(定时调用 gc.collect() ),并没有什么卵用。
于是开始搜索“Python 内存分析/泄露”关键词,出来一堆内存对象统计的库如 pympler,功能大同小异,都是获取内存中所有的对象呀,统计下对象个数呀,做一下 diff 呀。
安装了个 pymler,看了下其核心是调用 gc.get_objects() 获取到所有内存对象然后统计。然而依然并没有什么卵用,因为得到的是这样的东西:
===================== | =========== | ============
dict | 2627 | 3.07 MB
unicode | 1762 | 2.64 MB
str | 21614 | 2.34 MB
code | 7862 | 982.75 KB
type | 934 | 829.12 KB
list | 2307 | 264.00 KB
tuple | 2409 | 179.62 KB
weakref | 1499 | 128.82 KB
wrapper_descriptor | 1294 | 101.09 KB
set | 329 | 95.54 KB
getset_descriptor | 1054 | 74.11 KB
_sre.SRE_Pattern | 183 | 71.96 KB完全木有用,谁知道 dict 和 unicode 和 str 到底是什么地方构造的?
当然有问题还是要考虑解决的,第一反应时,用自定义类型替换代码里面的 dict, list, str 等内置类型。然而真正的代码里定义 dict,list,str 的地方很少,很多都是 json 反序列化、标准库对象内嵌等产生的内置类型。
我研究了下是否可以替换内置的 dict, list 等类型,并且在初始化的时候记录下行号,发现就算替换了内置类型,也必须显示调用 dict() list()的时候才会使用被替换的类型, {}, []产生的不可以。基本上这个思路也不可行了。
最后我考虑了下,将所有的对象序列化,定时存储到文件里,大概代码是这样的:
from pympler import summary, muppy
all_objects = muppy.get_objects()
with open('snapshot'+datetime.datetime.now().strftime("%Y%m%d-%H%M%S")+'.txt', 'wb') as f:
latest_snapshot = []
for item in all_objects:
try:
snap = str(type(item)) + ' ' + str(item)
latest_snapshot.append(snap)
except:
pass
latest_snapshot.sort()
for item in latest_snapshot:
f.write(item)
f.write('\n')
del latest_snapshot好了,现在我可以隔一段时间触发一次这段代码.
我之所以要把内存快照存到磁盘原因是,如果直接在程序里面比较两次时间点之间的对象列表,就需要引用上一个时间点的所有对象,会导致所有的对象都不会被释放。同样,如果我在内存比较序列化之后的对象(str(object)),还是会产生大量序列化的字符串,这些同样不会被释放。
最后一步,使用 vimdiff 对比不同时间点的快照文件:
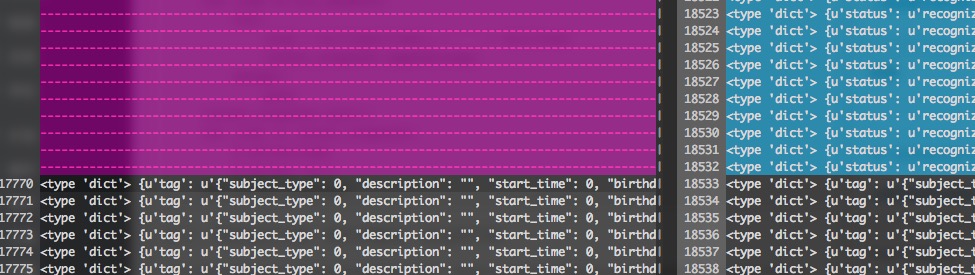
这下增加了什么对象,内容是什么就一目了然了。
最后,发现是把有一个 dict,一直在往里放东西,但是没有删除过,所以导致的越来越大。
最后我觉得 Python 内存泄露基本上就是循环引用(虽然我没遇到过),还有自增长的 list 和 dict 对象了。